🤝 people2vec: LA Hacks 2023 3rd Prize Overall
Awarded 3rd Place Overall as an entry for LA Hacks 2023. We use users’ YouTube watch history and match them with those with similar media interests via LLM and large CV model embeddings. Particularly, we visualize user interest overlap (and divergence) with video clouds (embedding PCA point clouds) to reveal similar interests while preserving privacy (i.e., without revealing the other person’s YouTube histories).

Think of the last time you made a meaningful connection. What were you talking about? That one really funny youtube video from years ago? The new marvel movie trailer? Some deep-dive analysis into a topic that really resonated with you? Nowadays, our interests and identities are often reflected in the content we consume. Yet it is not something we actually think about when forming new connections.
Many of us are in our comfort zone with our friend groups in college. But what about when we graduate, go to study abroad, or have to move somewhere for a new job? When you try to meet new people and talk to them for the first time, what’s your icebreaker going to be?
That’s why we made people2vec. A web app that matches you with people of similar interests, based on your YouTube watch histories.
Inspiration
The lot of us are all machine learning (ML) people, having worked with both natural language processing (NLP) and computer vision (CV) problems before, and we understand the importance of embeddings, i.e., vector representations of semantic information (e.g., text and images) that can be very helpful.
It seems like the only way to meet people nowadays is via dating apps, some based on looks, some based on “personality,” etc. However, oftentimes what bonds people together is their shared interests in media consumption, and one of the most popular platforms for doing so is YouTube. Why not recreate the excitement and fun of sharing your new favorite YouTube video with your friends, with people who you otherwise may not have met?
The name people2vec makes an ohmage to word2vec, the very original popular text embedding technique that kickstarted it all.
What it does

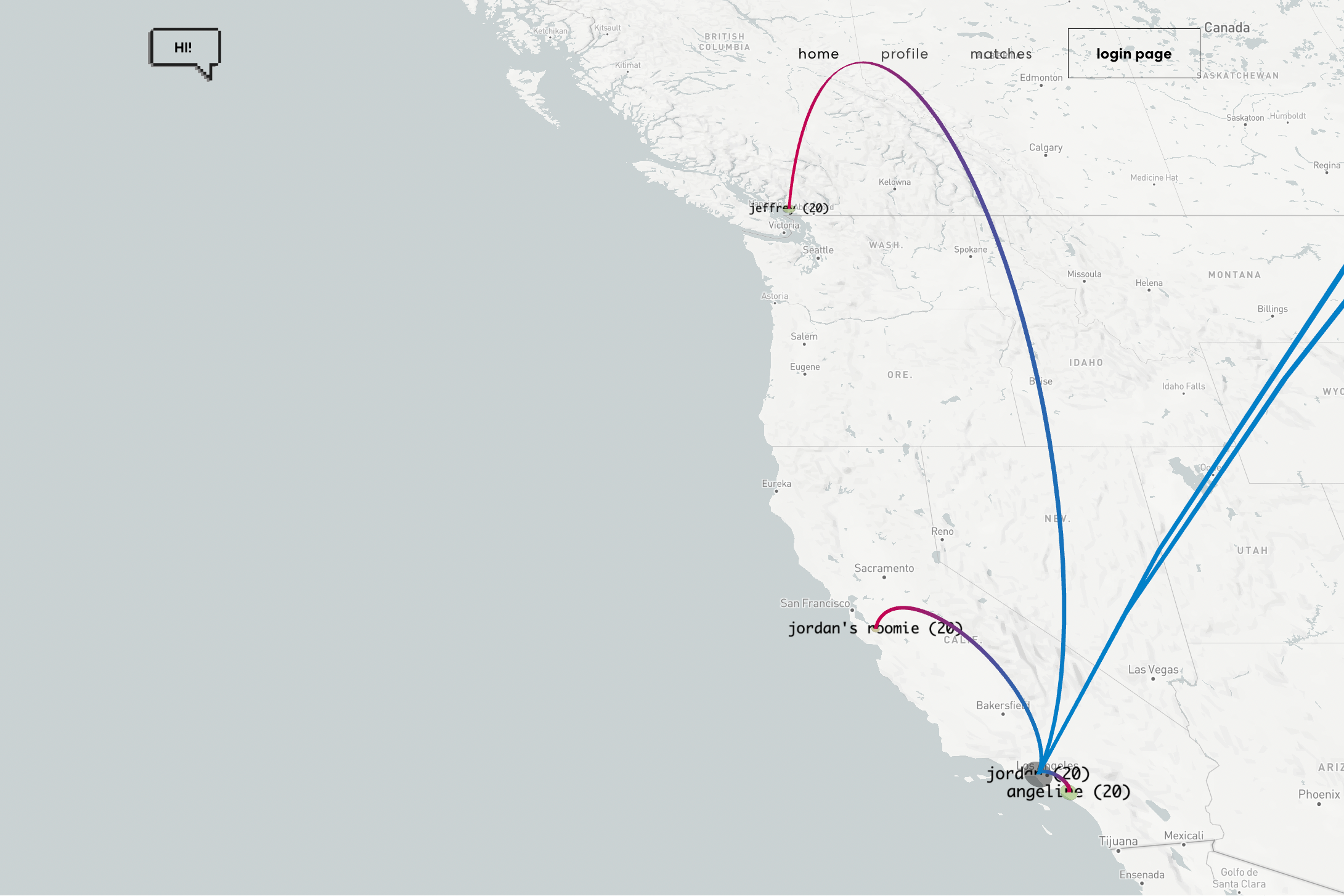
People2vec finds people with similar interests based on your social media activity. In particular, we use users’ YouTube watch history and match them with those with similar interests via embeddings from both NLP and CV methods. Additionally, we provide interesting visualizations that intuitively display how your YouTube interests match and differ with others.
How we built it

The people2vec tech stack consists of a Node.js and React.js frontend and Django backend. The NLP pipeline uses Cohere’s amazing API of their multilingual model (due to YouTube video titles having multiple languages) to obtain embeddings of video titles, and the CV pipeline uses PyTorch’s InceptionV3 with weights pretrained on ImageNet1K and the last classification layer set to identity. Particularly, we take inspiration from the Fréchet Inception Distance (FID) from generative CV, where we compute the similarity between two user’s YouTube video interests by comparing the distribution of their respective watch history videos’ title and thumbnail embeddings.
We embed TensorBoard’s PCA to visualize video title embeddings between two users, and we use YouTube’s API to fetch thumbnails. We also use Deck.GL and Google Maps’s Geocoding API for location-based information.
Challenges we ran into
One of the main challenges we ran into is API-related, particularly related to YouTube. We wanted to have a way to directly fetch watch history (and other analytics information of a user) by asking them to authenticate their Google account with us, but we quickly discovered that doing so is simply impossible, hence the relatively jank way of asking people to upload their Google Takeout data downloads.
Another challenge we ran into was linking everything together. We worked in quite compartmentalized ways in the beginning. Angeline developed the frontend, Jordan wrote the ML methods, Prateik handled the data parsing and processing, and Jeffrey built the backend. Each component worked well in their respective unit tests, but combining them soon proved to be a big challenge as there were many moving parts that relied on each other to be properly tested. We were, quite literally, assembling a plane as it was flying.
Accomplishments that we’re proud of
Jordan: Using embeddings and distribution comparison methods (FID scores) worked better than I expected, especially since I am combining many different APIs and file formats into flexible modules that allowed for easy and relatively efficient computation of a similarity measure between two embedding distributions.
Angeline: The design <3
Prateik: I am quite proud of getting the TensorBoard to work. The visualization ended up being way cooler looking than we first expected, and the path to getting it to work (hacking GitHub) was also quite arduous yet rewarding. Also, I parsed HTML with Regex. Take that computer scientists!
Jeffrey: I’m proud of not giving up and all the friends we made along the way (zero) ![]()
What we learned
We got to know GitHub way better. We learned the importance of a solid plan that still allows for flexibility (which we are still working on improving!). We grasped the difficulty of integrating machine learning models to full-stack applications and got better at knowing how to assemble these differing modules together. Most importantly, we learned how to work as a team <3
What’s next for people2vec
We think a great next direction is security related. Particularly, it is very possible to borrow aspects of federated learning to better preserve user privacy (especially with information like YouTube watch history). For example, we can do pre-processing (e.g., first-layer pass through the neural network) on the frontend (i.e., “locally,” or on the user’s device) to obtain some initial embedding that greatly obfuscates user data and complete the rest of the processing in the backend. This ensures that we can still extract information about the user’s YouTube video interests while not directly having a copy of their information.